文档理解与生成的交错式多模态模型朴素设计¶
评论: 本技术备忘录是对 2024 年(MSRA实习生期间)开发的原生交错式图像-文本大模态模型在设计上的回顾与反思。本文回忆了在该项目期间实施的部分工程决策、经验性观察和数学层面上的优化。下文所述的架构可能包含新颖的想法,也可能仅仅是利用了 2024 年及以前已经存在的既有技术。作为个人性质的回顾,本文省略了正式的学术引用,但我们对社区先前完成的那些令人惊叹的开拓性工作致以最深切的敬意。
简介¶
本项目的核心目标是实现一种原生统一的多模态架构,使其既能够向图像中写入文字,也能够从图像中读取内容。该方法并没有将视觉数据视为注入语言模型中的辅助连续嵌入,而是通过将离散的文本词表与量化后的视觉代码本合并为一个统一的组合词表,从而统一了输入流。
视觉分词器¶
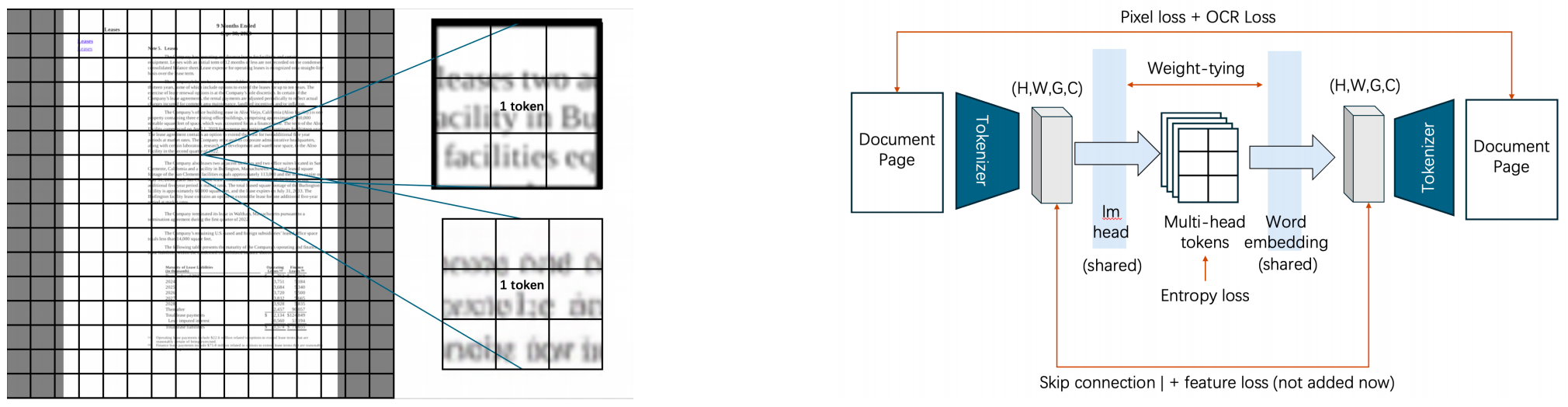
整体框架¶
数据¶
数据格式¶
为了训练一个能够解析和理解布局结构的交错式文档级模型,必须将空间结构直接传递给语言模型。我们尝试了两种不同的数据格式化范式,以训练模型如何以自回归的方式生成边界框和布局配置。
格式 A:显式空间锚定(带边界框) 为了显式引导文档布局解析,文本片段由结构化标签包裹,并配以绝对坐标:
<para><box><size{x1}><size{y1}><size{x2}><size{y2}></box>It's a good day...</para>... <image><size><size{w}><size{h}></size><image_pad1>...</image><para>...
格式 B:隐式空间推断(不带边界框) 该格式剥离了结构化坐标,转而任务化地要求模型隐式地学习空间布局的依赖关系:
<para>It's a good day...</para>... <image><size><size{w}><size{h}></size><image_pad1>...</image><para>...
然而,试图强迫一个紧凑的 2B 参数量骨干模型同时学习这两种数据格式被证明过于野心,这引入了过大的方差并阻碍了模型的收敛。因此,我们完全规范统一到了格式 A 上,以提供严格的布局约束。
数据源¶
-
arXiv 语料库: 一个以 OCR 为核心、包含密集页面布局的数据集。文本内容与边界框严格对齐,将语义单元直接映射到其在对应页面图像上的空间位置。
-
合成数据集: 为了增强布局的鲁棒性,我们从 FineWeb 中提取原始文本,并通过
PyMuPDF (fitz)将其编译为干净的 PDF 布局。合成文档利用了随机的字体族、字号、字重和颜色配置,以扩展数据的多样性。
多头视觉分词器¶
在开发离散视觉分词器时,我们确立了三个核心的经验性观察:
-
重建退化: 采用过大的视觉图像块尺寸会显著降低空间重建质量,并抹除细粒度的细节。
-
语义碎片化: 过度局部的、超细粒度的图像块无法捕获统一的语义。此类图像块往往只包含毫无意义的局部曲线,使得模型难以从中提取高层语义概念。
-
嵌入维度不匹配: 原生视觉码本的隐藏维度窄于 LLM 广阔的文本嵌入空间。
为了解决这些权衡问题,我们设计了一个多头视觉分词器。
我们没有将一个视觉图像块强行塞进庞大离散词表中的单个整数索引里,而是将一个富含全局语义的宽空间图像块通过 \(G\) 个不同的线性头进行投影。每个单独的头都指向全局图像码本矩阵中其自身特有的离散分配池。这使得每个视觉图像块产生一个复合整数向量 \(\boldsymbol{t} \in \mathbb{R}^{G}\),将多个整数绑定到单个图像块上,以确保高保真的重建质量。
为了解决第三点观察(嵌入宽度不匹配),这些投影头最后会被合并并投影到骨干模型的统一高维隐藏空间中。在我们的实验设置中,该骨干模型为 Gemma-2 2B。
在分词器训练期间,我们引入了多种辅助损失函数的组合,以专门针对文档生成任务调优其性能。
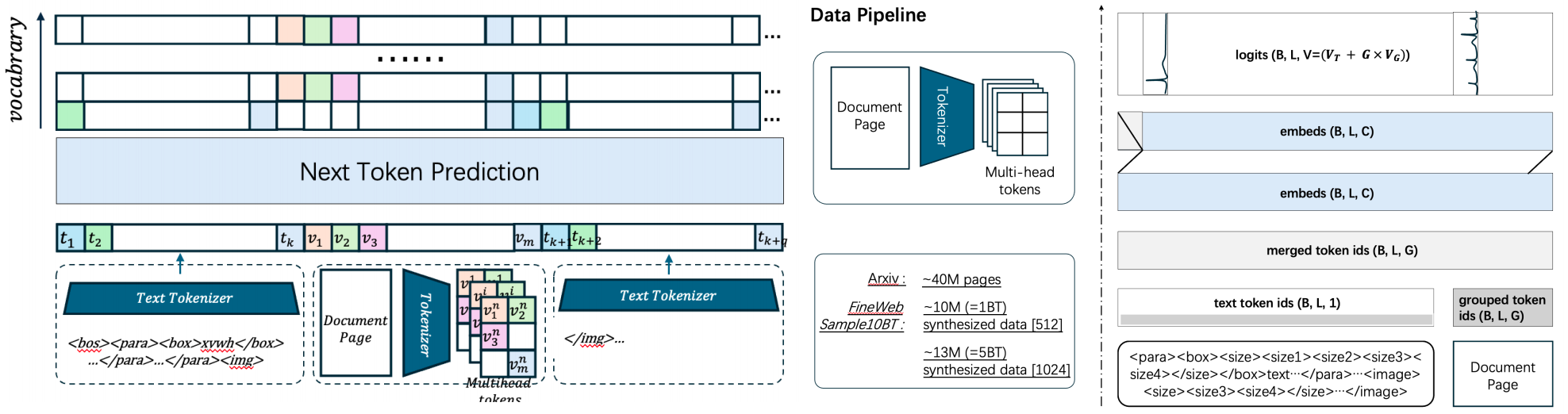
组合词表表示¶
该词表结构简单地将 \(G \times \text{codebook}\) 的条目附加在预先存在的文本词表之后。序列目标统一由向量序列 \(\boldsymbol{t} \in \mathbb{R}^{G}\) 表示:
-
对于图像 Token: \(\boldsymbol{t}\) 中的 \(G \times \text{integers}\) 映射到 \(G\) 个切分图像代码本中各自的索引。这些 \(G\) 个 ID 所对应的嵌入会被合并并投影到一个单一的联合嵌入向量中。
-
对于文本 Token: 出于计算便利性的考虑,\(\boldsymbol{t}\) 中的 \(G \times \text{integers}\) 会被复制为完全相同的数值,代表语言词表中的标准
token_id。而在文本嵌入层中,只有单个 Token ID 会被激活并用于绑定和检索语言嵌入。
这种统一的词表布局避免了训练期间特定模态的孤立。刻意将图像优化与文本优化割裂开来会扭曲下一个 Token 的概率分布,从而破坏我们希望 Transformer 原生习得的多模态协同效应。
需要澄清的是,我们猜测 2024 年及以前的一些模型在视觉任务上表现不佳的核心原因之一,在于模型无法有效区分“视觉词”与“文本词”,而在我们的设计初衷里,这两者不应混为一谈。
我们可以用语言空间内部的现象做一个类比:正如文本中的“麻雀”、“老鹰”和“企鹅”虽然都归属于“鸟”这一大类,但它们在嵌入空间中依然作为独立的个体占据着相互平行的独特位置。
同理,从图像中提取的视觉概念,也不应该被强行压缩映射到已有的文本坐标上。相反,视觉上的“鸟”并不等同于文本中的“鸟”;它们更像是同一个概念家族下的不同物种(互为近义词),在同一个高维空间中保持相互平行。至于它们之间具体的几何和语义边界,应当完全交给模型和训练数据去动态演化和区分。
混合目标交叉熵损失¶
给定一个词表集合 \(\mathcal{V}\),真实分布概率 \(p_t\),以及预测的 Logit \(l_t\),带有 One-Hot 标签的标准交叉熵损失可以简化为仅追踪激活的正样本 Token:
其梯度传播公式为:
在处理非 One-Hot 的目标时,标准实现会引入庞大向量 \(\boldsymbol{p} \in \mathbb{R}^{|\mathcal{V}|}\) 与 \(\boldsymbol{l} \in \mathbb{R}^{|\mathcal{V}|}\) 之间的全密集乘法,从而导致严重的显存开销。
为了对此进行优化,我们通过 torch.gather 将目标追踪严格限制在一个稀疏的子集索引空间 \(\mathcal{G} \subseteq \mathcal{V}\) 内:
为了扩展执行规模,全局词表的 Logits 被分割并分布在 \(N\) 张物理加速卡上。在管理本地分片 \(\mathcal{V}^k\) 的给定计算卡 \(k\) 上,分布式规约的计算如下:
$\(\begin{aligned}
\mathcal{L}_{\text{CE, neg}}^{k} &= \sum_{i \in \mathcal{V^k}} \exp(l_i) ,\quad \mathcal{L}_{\text{CE, neg}} = \log\sum_{k} \mathcal{L}_{\text{CE, neg}}^{k} \\
\mathcal{L}_{\text{CE, pos}}^{k} &= \sum_{t \in \mathcal{G} \cap \mathcal{V^k} } p_t l_t ,\quad \mathcal{L}_{\text{CE, pos}} = \sum_{k}\mathcal{L}_{\text{CE, pos}}^{k} \\
\mathcal{L}_{\text{CE}} &= \mathcal{L}_{\text{CE, neg}} - \mathcal{L}_{\text{CE, pos}}
\end{aligned}\)$
在反向传播期间,我们在正向传播中预先计算并缓存全局 Softmax 状态 \(S(l_i) = \exp(l_i) / \sum_{k}\mathcal{L}_{\text{CE, neg}}^{k}\),以避免重复的激活值显存实例化。然后,我们应用 torch.gather 仅提取 \(S(l_i)\) 中的激活项,减去目标概率 \(p_i\),并使用原地的 scatter 操作来填充梯度,从而绕过了全量张量的显存分配。
注意力掩码¶
我们探索了两种不同的自回归序列掩码策略,以管理文本与图像的交错。
策略 A:纯粹的下一个 Token 预测¶
第一种选择将标准的因果下一个 Token 预测,应用于所有模态。它在单个统一序列中处理文本和离散图像 Token,将图像索引视作与标准文本 Token 完全一致。这强硬地要求模型完全自主地学会模态之间的切换。由于其鲁棒性和工程上的简单性,我们选用该策略。
策略 B:混合下个块预测¶
另一种交替范式对文本片段强制执行标准的序列化 NTP,同时在图像区域切换为并行化的块生成。
当模型遇到布局标签 <image><size><size{w}><size{h}></size> 时,它会触发并切换到后续 \(w \times h\) 个 Token 的图像模式。此时因果注意力矩阵会被修改为并行块提取。
注意力掩码的布局遵循以下因果结构:
| AttnMask | |||||||
|---|---|---|---|---|---|---|---|
<size{h}> |
1 | ||||||
</size> |
1 | 1 | |||||
<p1> |
1 | 1 | 1 | 1 | 1 | ||
<p2> |
1 | 1 | 1 | 1 | 1 | ||
<p3> |
1 | 1 | 1 | 1 | 1 | ||
</image> |
1 | 1 | 1 | 1 | 1 | 1 | |
<para> |
1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q / K | <size{h}> |
</size> |
<p1> |
<p2> |
<p3> |
</image> |
<para> |
在此块掩码设置下,预测目标移动如下:
| Prediction | |||||||
|---|---|---|---|---|---|---|---|
| Source | <size{h}> |
</size> |
MASK |
MASK |
MASK |
</image> |
<para> |
| Target | </size> |
NULL |
<p1> |
<p2> |
<p3> |
<para> |
NEXT |
尽管这种混合方法偏离了我们的核心信念,即在统一嵌入空间中所有 Token 都应保持完美的平等和一致,但它为并行化视觉合成提供了一个非常有吸引力的框架。
未来愿景¶
站在 2026 年的技术视角审视,我们 2024 年设计的架构局限性显得有些朴素。转向隐式多模态语言模型无疑会带来更优的特征表示和生成质量。
然而,在这些局限性之下,仍然潜藏着一个巨大的、尚未被探索的设计空间,指向了一条截然不同的道路。我们相信,仿生学仍然是多模态架构中一条极具吸引力的交替路径。人类视觉处理世界的方式并不是通过将海量、高分辨率的像素矩阵强行塞进一个静态的注意力窗口;相反,它依赖于连续的、低分辨率的视频流,并结合了主动的、意图驱动的扫描。
这启发了 Glimpse Model 的概念,这是一种由三个核心组件定义的“主动感知”架构:
-
固定分辨率编码器: 编码器(或分词器)被彻底锁定在一个静态、恒定不变的分辨率中,从而允许底层硬件和注意力算子内核进行极限优化。例如,视觉输入被编码为具有严格固定序列长度的自回归信息流,从而确保其能更无缝地融入基于文本的Concept Backbone中。
-
裁剪与缩放工具: 一个直接由语言模型骨干的动作 Token控制的执行工具。它充当数字版的“Fovea”,从原始输入中动态切下特定的高分辨率感兴趣区域,并将其归一化后重新输入到固定编码器中。
-
缩放的全局视图: 整个视觉领域的一个深度降采样、模糊化的抽象表示。这充当了模型的“Peripheral Vision”,在不导致序列显存爆炸的前提下,提供持久的空间和拓扑上下文。最终,由模型自己来决定看哪里、何时看以及聚焦于什么。
我们希望在未来的某一天,一种优雅的 Glimpse Model 会从开源社区中诞生并重塑视觉任务。