注意力中隐藏的递推结构:Flash Attention介绍
原文链接: https://arxiv.org/abs/2205.14135
原文链接: https://arxiv.org/abs/2307.08691
代码链接: https://github.com/Dao-AILab/flash-attention
声明: 本文为个人阅读笔记。部分推导为自行完成,可能存在错误,后续需与代码实现交叉验证。
标准注意力
前向传播
\[\begin{aligned}
\mathbf{O} &=
\text{Diag}\left(
\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right)\boldsymbol{1}\right)^{-1}
\left(
\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)\mathbf{V}
\end{aligned}\]

反向传播
在推导标准注意力的反向传播之前,先考虑一个简单情形:
\[\begin{aligned}
\mathbf{Y} &= \text{Diag}\left( \mathbf{X}\boldsymbol{1}\right)^{-1}
\\ \\ \Rightarrow
\delta \mathbf{X} &=
\text{diag}\left(
- \mathbf{Y}^\top \delta \mathbf{Y} \mathbf{Y}^\top
\right) \boldsymbol{1}^\top
=
- \text{diag}\left(
\mathbf{Y} \delta \mathbf{Y} \mathbf{Y}
\right) \boldsymbol{1}^\top
=
- \mathbf{Y}^2 \text{diag}\left(
\delta \mathbf{Y}
\right) \boldsymbol{1}^\top
\end{aligned}\]
由此可以推导出标准注意力的完整反向传播:
\[\begin{aligned}
\mathbf{O} &=
\text{Diag}\left(
\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right)\boldsymbol{1}\right)^{-1}
\left(
\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)\mathbf{V}
\\
\\
\Rightarrow
\delta \left(\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)
&=
\text{Diag}\left(\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right) \boldsymbol{1}\right)^{-1}
\delta \mathbf{O}
\mathbf{V}^\top
\\ &-
\text{Diag}\left(\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right) \boldsymbol{1}\right)^{-2}
\text{diag}\left(
\delta \mathbf{O} \mathbf{V}^\top
\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right)^\top\right)
\boldsymbol{1}^\top
\\ &=
\text{Diag}\left(\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right) \boldsymbol{1}\right)^{-1}
\left(
\delta \mathbf{O} \mathbf{V}^\top
-
\text{diag}\left(\delta \mathbf{O} \mathbf{O}^\top
\right)
\boldsymbol{1}^\top
\right)
\\ \\ \Rightarrow
\delta \mathbf{V} &=
\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right)^\top
\text{Diag}\left(\left(\exp(\mathbf{Q}\mathbf{K}^\top ) \odot \mathbf{M}\right) \boldsymbol{1} \right)^{-1}
\delta \mathbf{O}
\\ \\
\delta \mathbf{Q} &= \left(
\delta \left(\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)
\odot \left(\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)
\right) \mathbf{K}
\\ \\
\delta \mathbf{K} &= \left(
\delta \left(\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)
\odot \left(\exp(\mathbf{Q}\mathbf{K}^\top) \odot \mathbf{M}\right)
\right)^\top \mathbf{Q}
\end{aligned}\]
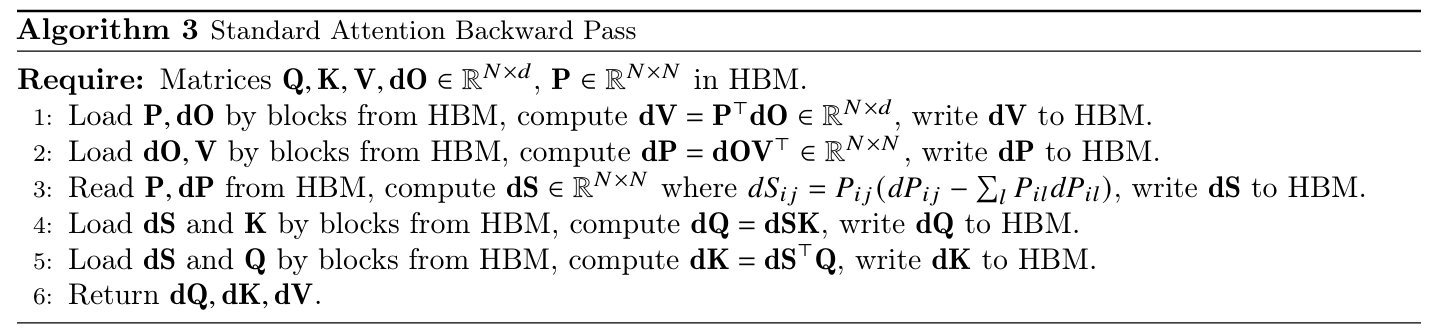
标准注意力背后隐藏的递推结构
递推模式
评论: 我认为设计分块算法的关键在于找到一种递推关系,使得每个局部块都能与全局信息关联起来。因此,我们首先要获取 softmax 点积注意力背后隐藏的递推模式。
考虑
\[\begin{aligned}
\mathbf{O}
&= \frac{\exp(\mathbf{Q}\mathbf{K}^\top)}{\sum_k \exp(\mathbf{Q}\mathbf{K}^\top)} \mathbf{V}
\quad \Leftrightarrow \quad
\mathbf{O} =
\text{Diag}\left( \exp(\mathbf{Q}\mathbf{K}^\top) \boldsymbol{1}\right)^{-1}
\exp(\mathbf{Q}\mathbf{K}^\top)\mathbf{V}
\\ \\ \Leftrightarrow
\boldsymbol{o}_t
&= \frac{ \sum_{i=1}^L \boldsymbol{v}_i \exp(\boldsymbol{k}_i^\top\boldsymbol{q}_t) }
{\sum_{i=1}^L \exp(\boldsymbol{k}_i^\top\boldsymbol{q}_t)}
\end{aligned}\]
我们定义
\[\begin{aligned}
\boldsymbol{a}^j_t
=
\sum_{i=1}^t \boldsymbol{v}_i \exp(\boldsymbol{k}_i^\top\boldsymbol{q}_j)
,\quad
l^j_t = \sum_{i=1}^t \exp(\boldsymbol{k}_i^\top\boldsymbol{q}_j)
,\quad
\boldsymbol{a}^t_L = l^t_L \boldsymbol{o}_t
\end{aligned}\]
则有如下递推关系
\[\begin{aligned}
l^j_t &= l^j_{t-1} + \exp(\boldsymbol{k}_t^\top\boldsymbol{q}_j)
\\
\\
\boldsymbol{a}^j_{t} &= \sum_{i=1}^t \boldsymbol{v}_i \exp(\boldsymbol{k}_i^\top\boldsymbol{q}_j)
=
\boldsymbol{a}^j_{t-1}
+ \boldsymbol{v}_t \exp(\boldsymbol{k}_t^\top\boldsymbol{q}_j)
\end{aligned}\]
分块递推模式
下文中 \(\mathbf{M}\) 表示因果掩码或无掩码。
\[\begin{aligned}
\mathbf{O}_{[t]} &= \text{Diag}\left(\boldsymbol{ll}^{[t]}_{[L]}\right)^{-1} \mathbf{A}^{[t]}_{[L]}
\\ \\
\boldsymbol{ll}^{[j]}_{[t]} &= \boldsymbol{ll}^{[j]}_{[t-1]}
+
\left(\exp \left(\mathbf{Q}_{[j]}\mathbf{K}_{[t]}^\top\right) \odot \mathbf{M}\right) \boldsymbol{1}
\\ \\
\mathbf{A}^{[j]}_{[t]} &=
\mathbf{A}^{[j]}_{[t-1]}
+
\left(\exp \left(\mathbf{Q}_{[j]}\mathbf{K}_{[t]}^\top\right) \odot \mathbf{M}\right) \mathbf{V}_{[t]}
\end{aligned}\]
引入如下记号
\[\begin{aligned}
\mathbf{S}_{[t],[\tau]} &= \mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top
\in \mathbb{R}^{N \times M}
,\quad
\boldsymbol{m}_{[t],\tau}
\in \mathbb{R}^{N}
\\ \\
\mathbf{P}_{[t],[\tau]} &=
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)^{-1}
\left(
\exp \left(\mathbf{S}_{[t],[\tau]}\right)
\odot \mathbf{M}
\right)
\in \mathbb{R}^{N \times M}
\\ \\
\boldsymbol{l}_{[t],[\tau]} &= \mathbf{P}_{[t],[\tau]} \boldsymbol{1}
\in \mathbb{R}^{N}
\end{aligned}\]
则有
\[\begin{aligned}
\boldsymbol{l}^{[t]}_{[\tau]} &=
\boldsymbol{ll}^{[t]}_{[\tau]} \oslash \boldsymbol{m}^{\tau}_{[t]}
=
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\boldsymbol{l}^{[t]}_{[\tau-1]}
+ \text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\boldsymbol{l}_{[t],[\tau]}
\\ \\
\mathbf{A}^{[t]}_{[\tau]} &= \mathbf{A}^{[t]}_{[\tau-1]}
+ \text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\mathbf{P}_{[t],[\tau]}\mathbf{V}_{[\tau]}
\end{aligned}\]
带在线 Softmax 重缩放的分块模式
为保证数值稳定性,我们通常对 softmax 采用重缩放技巧,即以历史 \(\mathbf{QK}^\top\) 的行最大值的指数作为缩放因子。定义:
\[\begin{aligned}
\boldsymbol{m}^{\tau}_{[t]} &=
\max(\boldsymbol{m}^{\tau-1}_{[t]}, \boldsymbol{m}_{[t],\tau})
\\
\\
\boldsymbol{l}^{[t]}_{[\tau]} &=
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\boldsymbol{l}^{[t]}_{[\tau-1]}
+ \text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\boldsymbol{l}_{[t],[\tau]}
\\
\\
\mathbf{C}^{[t]}_{[\tau]} &=
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\mathbf{A}^{[t]}_{[\tau]}
\\&=
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\mathbf{C}^{[t]}_{[\tau-1]}
+
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\mathbf{P}_{[t],[\tau]}\mathbf{V}_{[\tau]}
\\
\\
\mathbf{O}^{[t]} &=
\text{Diag}\left(\boldsymbol{l}^{[t]}_{L}\right)^{-1}
\mathbf{C}^{[t]}_{[L]}
\end{aligned}\]
至此,加上内外循环的交换以及 logsumexp 缩放因子的引入位置,我们就推导出了 FlashAttention v1/v2 的核心逻辑。


Flash Attention 反向传播
评论: 行最大值的指数 \(\boldsymbol{m}\) 虽然由输入计算得到,但在梯度计算时可视为常数。而 \(\boldsymbol{l}\) 是输入的函数,梯度会流经它。
回顾前向传播
\[\begin{aligned}
\mathbf{P}_{[t],[\tau]} &=
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)^{-1}
\left(
\exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top \right)\odot \mathbf{M}
\right)
\in \mathbb{R}^{N \times M}
\\
\\
\boldsymbol{l}^{[t]}_{[\tau]} &=
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\boldsymbol{l}^{[t]}_{[\tau-1]}
+ \text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\mathbf{P}_{[t],[\tau]} \boldsymbol{1}
\\
\\
\mathbf{C}^{[t]}_{[\tau]} &=
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\mathbf{C}^{[t]}_{[\tau-1]}
+
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\mathbf{P}_{[t],[\tau]}\mathbf{V}_{[\tau]}
\\
\\
\mathbf{O}^{[t]} &=
\text{Diag}\left(\boldsymbol{l}^{[t]}_{L}\right)^{-1}
\mathbf{C}^{[t]}_{[L]}
\end{aligned}\]
梯度推导
评论: 反向传播的核心思想是用重计算替代存储。我们无需保存前向传播中完整的注意力矩阵 \(\mathbf{P}\),只需存储 \(\boldsymbol{l}\) 和 \(\boldsymbol{m}\),然后在反向传播过程中逐块重新计算注意力矩阵。
假设前向传播中已存储 \(\boldsymbol{l}\) 和 \(\boldsymbol{m}\),我们从\(\mathbf{O}^{[t]}\) 开始推导反向传播:
\[\begin{aligned}
\delta \mathbf{C}^{[t]}_{[L]} &=
\text{Diag}\left(\boldsymbol{l}^{[t]}_{[L]}\right)^{-1}
\delta \mathbf{O}^{[t]}
\\
\\
\delta \boldsymbol{l}^{[t]}_{[L]} &= -
\text{diag}\left(
\text{Diag}\left(\boldsymbol{l}^{[t]}_{[L]}\right)^{-\top}
\left(\delta \mathbf{O}^{[t]} (\mathbf{C}^{[t]}_{[L]})^\top \right)
\text{Diag}\left(\boldsymbol{l}^{[t]}_{[L]}\right)^{-\top}
\right)
= -
\text{diag}\left(\delta \mathbf{O}^{[t]} (\mathbf{O}^{[t]})^\top \right)
\oslash \boldsymbol{l}^{[t]}_{[L]}
\\
\\
\delta \boldsymbol{l}^{[t]}_{[\tau-1]}
&=
\left(
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\right)^\top
\delta \boldsymbol{l}^{[t]}_{[\tau]}
=
\left(
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^L_{[t]}\right)^{-1}
\right)^\top
\delta \boldsymbol{l}^{[t]}_{[L]}
\\
\\
\delta \mathbf{C}^{[t]}_{[\tau-1]}
&=
\left(
\text{Diag}\left(\boldsymbol{m}^{\tau-1}_{[t]}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\right)^\top
\delta \mathbf{C}^{[t]}_{[\tau]}
\\
\\
\left.\delta \mathbf{V}_{[\tau]}\right|_{\text{from [t]}}
&= \mathbf{P}_{[t],[\tau]}^\top
\left(
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\right)^\top
\delta \mathbf{C}^{[t]}_{[\tau]}
=
\left(
\exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top\right)
\odot \mathbf{M}
\right)^\top
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\delta \mathbf{C}^{[t]}_{[\tau]}
\\
\\
\delta \mathbf{P}_{[t],[\tau]}
&=
\left(
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\right)^\top
\left(
\delta \boldsymbol{l}^{[t]}_{[\tau]}
\boldsymbol{1}^\top
+
\delta \mathbf{C}^{[t]}_{[\tau]} \mathbf{V}_{[\tau]}^\top
\right)
\\ &=
\left(
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^L_{[t]}\right)^{-1}
\right)^\top
\delta \mathbf{l}^{[t]}_{[L]}
\boldsymbol{1}^\top
+
\left(
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)
\text{Diag}\left(\boldsymbol{m}^\tau_{[t]}\right)^{-1}
\right)^\top
\delta \mathbf{C}^{[t]}_{[\tau]} \mathbf{V}_{[\tau]}^\top
\\
\\
\left.\delta \mathbf{Q}_{[t]}\right|_{\text{from } \mathbf{P}_{[t],[\tau]}}
&=
\left(
\delta \exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top\right)
\odot \exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top\right)
\right) \mathbf{K}_{[\tau]}
\\ &=
\left(
\text{Diag}\left(\boldsymbol{m}_{[t],\tau}\right)^{-1}
\delta \mathbf{P}_{[t],[\tau]} \odot \mathbf{M}
\odot \exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top\right)
\right) \mathbf{K}_{[\tau]}
\\&=
\left(
\delta \mathbf{P}_{[t],[\tau]} \odot \mathbf{P}_{[t],[\tau]}
\right) \mathbf{K}_{[\tau]}
\\
\\
\left.\delta \mathbf{K}_{[\tau]}\right|_{\text{from } \mathbf{P}_{[t],[\tau]}}
&=
\left(
\delta \exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top\right)
\odot \exp \left(\mathbf{Q}_{[t]}\mathbf{K}_{[\tau]}^\top\right)
\right) ^\top \mathbf{Q}_{[t]}
\\ &=
\left(
\delta \mathbf{P}_{[t],[\tau]} \odot \mathbf{P}_{[t],[\tau]}
\right) ^\top \mathbf{Q}_{[t]}
\end{aligned}\]

