阅读笔记: Kimi Delta Attention
原文链接: https://arxiv.org/pdf/2510.26692
代码链接: https://github.com/fla-org/flash-linear-attention
声明: These are personal reading notes. Some derivations are my own and may be incorrect, so they should be cross-checked against the code later.
一、动机
- 使用细粒度门控改进 delta rule
二、符号约定
- 使用 \(\mathbf{S, Q}\) 等粗体大写字母表示矩阵
- 使用 \(\mathbf{q}_t, \mathbf{k}_t\) 等表示列向量(即 \([d, 1]\) 的形式),矩阵则是 \([L, d]\) 的形式,因此会有额外的转置操作
- 使用 \(W_t\) 等表示可学习参数
- 使用 \(\mathbf{q}_t\) 表示 \(\mathbf{Q}\) 的第 \(t\) 行
- \(\square_{[t]} = \square_{[t]}^{1:C} \in \mathbb{R}^{C \times d}\) 表示第 \(t\) 个 chunk,其中 \(\square \in { \mathbf{Q, K, V, \dots} }\)
三、背景
- Gated Linear Attention
- Online Learning
- DeltaNet and Gated DeltaNet
四、Kimi Delta Attention
前向传播
评论: 这里再次应用了 WY 表示法 (即假设 P 可以写成 X - WY 的形式)
原始公式:
\[\begin{aligned}
\mathbf{S}_t
&= \mathbf{S}_{t-1}
\text{Diag}(\boldsymbol{\alpha}_t)
(\mathbf{I} - \beta_t \boldsymbol{k}_t \boldsymbol{k}_t^\top)
+
\beta_t \boldsymbol{v}_t \boldsymbol{k}_t^\top
\in \mathbb{R}^{d_v \times d_k}
\\
\\
\boldsymbol{o}_t
&= \mathbf{S}_{t}\boldsymbol{q}_t
\end{aligned}\]
接下来,遵循 DeltaNet 的推导,定义块级符号和以下辅助量:
\[\begin{aligned}
\mathbf{P}_{[t]}^{r} &= \prod_{i=t C + 1}^{t C + r}
\text{Diag}(\boldsymbol{\alpha}_i)
(\mathbf{I} - \beta_{i} \boldsymbol{k}_{i} \boldsymbol{k}_{i}^{\top})
\in \mathbb{R}^{d_k \times d_k}
\\
\\
\mathbf{H}_{[t]}^{r} &= \sum_{i=tC + 1}^{tC + r}
\beta_{i} (\boldsymbol{v}_{i} \boldsymbol{k}_{i}^{\top})
\prod_{j=i + 1}^{t C + r}
\text{Diag}(\boldsymbol{\alpha}_j)
(\mathbf{I} - \beta_{j} \boldsymbol{k}_{j} \boldsymbol{k}_{j}^{\top})
\in \mathbb{R}^{d_v \times d_k}
\end{aligned}\]
然后,块级状态可以写为:
\[\begin{aligned}
\mathbf{S}_{[t]}^{r}
=
\mathbf{S}_{[t-1]}^{C}
\mathbf{P}_{[t]}^{r} + \mathbf{H}_{[t]}^{r}
, \quad
\text{where }
\mathbf{S}_{[-1]}^{C} = \mathbf{0}
\end{aligned}\]
另一方面,假设:
\[\begin{aligned}
\mathbf{S}_t = \sum_{i=1}^{t}
\text{Diag}(\boldsymbol{\eta}_t)
\text{Diag}(\boldsymbol{\xi}_i)
\boldsymbol{u}_i
\boldsymbol{k}_i^\top
\text{Diag}(\boldsymbol{\epsilon}_i)
\text{Diag}(\boldsymbol{\gamma}_t)
\end{aligned}\]
利用数学归纳法,我们得到:
\[\begin{aligned}
\mathbf{S}_t &=
\mathbf{S}_{t-1}
\text{Diag}(\boldsymbol{\alpha}_t)
+ \beta_t \left(
\boldsymbol{v}_t -
\mathbf{S}_{t-1}
\text{Diag}(\boldsymbol{\alpha}_t)
\boldsymbol{k}_t
\right) \boldsymbol{k}_t^\top
\\&=
\sum_{i=1}^{t-1}
\text{Diag}(\boldsymbol{\eta}_{t-1})
\text{Diag}(\boldsymbol{\xi}_i)
\boldsymbol{u}_i
\boldsymbol{k}_i^\top
\text{Diag}(\boldsymbol{\epsilon}_i)
\text{Diag}(\boldsymbol{\gamma}_{t-1})
\text{Diag}(\boldsymbol{\alpha}_{t})
\\&+ \beta_t \left(
\boldsymbol{v}_t -
\sum_{i=1}^{t-1}
\text{Diag}(\boldsymbol{\eta}_{t-1})
\text{Diag}(\boldsymbol{\xi}_i)
\boldsymbol{u}_i
\boldsymbol{k}_i^\top
\text{Diag}(\boldsymbol{\epsilon}_i)
\text{Diag}(\boldsymbol{\gamma}_{t-1})
\text{Diag}(\boldsymbol{\alpha}_{t})
\boldsymbol{k}_t
\right) \boldsymbol{k}_t^\top
\\&=
\sum_{i=1}^{t}
\text{Diag}(\boldsymbol{\eta}_{t})
\text{Diag}(\boldsymbol{\xi}_i)
\boldsymbol{u}_i
\boldsymbol{k}_i^\top
\text{Diag}(\boldsymbol{\epsilon}_i)
\text{Diag}(\boldsymbol{\gamma}_{t})
\end{aligned}\]
在我们设置如下参数之后:
\[\begin{aligned}
\text{Diag}(\boldsymbol{\gamma}_t)
=
\prod_{i=1}^t
\text{Diag}(\boldsymbol{\alpha}_i)
,\quad
\text{Diag}(\boldsymbol{\eta}_t) = \mathbf{I}
,\quad
\text{Diag}(\boldsymbol{\epsilon}_t)
= \text{Diag}(\boldsymbol{\gamma}_t)^{-1}
\end{aligned}\]
那么我们很容易得到:
\[\begin{aligned}
\boldsymbol{u}_t
&=
\beta_t
\text{Diag}(\boldsymbol{\xi}_t)^{-1}
\left(
\boldsymbol{v}_t -
\sum_{i=1}^{t-1}
\text{Diag}(\boldsymbol{\xi}_i)
\boldsymbol{u}_i
\boldsymbol{k}_i^\top
\text{Diag}(\boldsymbol{\epsilon}_i)
\text{Diag}(\boldsymbol{\gamma}_{t})
\boldsymbol{k}_t
\right)
\end{aligned}\]
将 \xi 吸收进 u 后,我们最终得到:
\[\begin{aligned}
\mathbf{S}_t = \sum_{i=1}^{t} \boldsymbol{u}_i
\left(\text{Diag}(\boldsymbol{\gamma}_i)^{-1} \boldsymbol{k}_i\right)^\top
\text{Diag}(\boldsymbol{\gamma}_t)
,\quad
\boldsymbol{u}_t
&=
\beta_t
\left(
\boldsymbol{v}_t -
\sum_{i=1}^{t-1}
\boldsymbol{u}_i
\left(\text{Diag}(\boldsymbol{\gamma}_i)^{-1} \boldsymbol{k}_i\right)^\top
\left(\text{Diag}(\boldsymbol{\gamma}_{t}) \boldsymbol{k}_t\right)
\right)
\end{aligned}\]
这与 Gated DeltaNet 中几乎完全相同。
同时,形如 (I - beta_t k_t k_t^T) 的 Householder变换 的乘积,总是可以使用 WY表示法 写成低秩形式。因此我们进一步推导它,再次使用几乎相同的归纳过程。
当 k = 0 时,我们有:
\[\begin{aligned}
\mathbf{P}_{[t]}^{r} = \text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\end{aligned}\]
因此我们假设:
\[\begin{aligned}
\mathbf{P}_{[t]}^{r} = \text{Diag}(\boldsymbol{\gamma}_{[t]}^r) - \sum_{i=1}^{r}
\text{Diag}(\boldsymbol{\eta}_{[t]}^r)
\text{Diag}(\boldsymbol{\xi}_{[t]}^i)
\boldsymbol{w}_{[t]}^{i} \boldsymbol{k}_{[t]}^{i \top}
\text{Diag}(\boldsymbol{\epsilon}_{[t]}^i)
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\end{aligned}\]
然后我们有:
\[\begin{aligned}
\mathbf{P}_{[t]}^{r}
&=
\mathbf{P}_{[t]}^{r-1}
\text{Diag}(\boldsymbol{\alpha}_{[t]}^r)
(\mathbf{I} - \beta_{[t]}^r \boldsymbol{k}_{[t]}^r \boldsymbol{k}_{[t]}^{r\top})
\\ \\&=
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
-
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\beta_{[t]}^r \boldsymbol{k}_{[t]}^r \boldsymbol{k}_{[t]}^{r\top}
\\ \\&-
\sum_{i=1}^{r-1}
\text{Diag}(\boldsymbol{\eta}_{[t]}^{r-1})
\text{Diag}(\boldsymbol{\xi}_{[t]}^i)
\boldsymbol{w}_{[t]}^{i} \boldsymbol{k}_{[t]}^{i \top}
\text{Diag}(\boldsymbol{\epsilon}_{[t]}^i)
\text{Diag}(\boldsymbol{\gamma}_{[t]}^{r-1})
\\ \\&+
\sum_{i=1}^{r-1}
\text{Diag}(\boldsymbol{\eta}_{[t]}^{r-1})
\text{Diag}(\boldsymbol{\xi}_{[t]}^i)
\boldsymbol{w}_{[t]}^{i} \boldsymbol{k}_{[t]}^{i \top}
\text{Diag}(\boldsymbol{\epsilon}_{[t]}^i)
\text{Diag}(\boldsymbol{\gamma}_{[t]}^{r-1})
\text{Diag}(\boldsymbol{\alpha}_{[t]}^r)
\beta_{[t]}^r \boldsymbol{k}_{[t]}^r \boldsymbol{k}_{[t]}^{r\top}
\end{aligned}\]
通过消去同类项、如下设置参数并将 \xi 吸收进 w,我们得到:
\[\begin{aligned}
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)
&=
\prod_{j=1}^i
\text{Diag}(\boldsymbol{\alpha}_{[t]}^j)
,\quad
\text{Diag}(\boldsymbol{\eta}_{[t]}^i) = \mathbf{I}
,\quad
\text{Diag}(\boldsymbol{\epsilon}_{[t]}^i)
= \text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\\
\\
\boldsymbol{w}_{[t]}^{r}
&=
\beta_{[t]}^r
\left(\mathbf{I} -
\sum_{i=1}^{r-1}
\boldsymbol{w}_{[t]}^{i}
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\boldsymbol{k}_{[t]}^{i}
\right)^\top
\right)
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\boldsymbol{k}_{[t]}^r
\\
\\
\mathbf{P}_{[t]}^{r} &=
\left(\mathbf{I}- \sum_{i=1}^{r}
\boldsymbol{w}_{[t]}^{i}
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\boldsymbol{k}_{[t]}^{i}
\right)^\top
\right)
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\end{aligned}\]
将其代入块级递推中得到:
\[\begin{aligned}
\mathbf{S}_{[t]}^{r}
&=
\mathbf{S}_{[t-1]}^{C}
\left(\mathbf{I}- \sum_{i=1}^{r}
\boldsymbol{w}_{[t]}^{i}
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\boldsymbol{k}_{[t]}^{i}
\right)^\top
\right)
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\\&+
\sum_{i=1}^{r} \boldsymbol{u}_{[t]}^i
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\boldsymbol{k}_{[t]}^i\right)^\top
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\\&=
\mathbf{S}_{[t-1]}^{C}
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
+
\sum_{i=1}^{r}
\left(
\boldsymbol{u}_{[t]}^i
-
\mathbf{S}_{[t-1]}^{C}
\boldsymbol{w}_{[t]}^{i}
\right)
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\boldsymbol{k}_{[t]}^{i}
\right)^\top
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\\
\\
\boldsymbol{o}_{[t]}^{r}
&=
\mathbf{S}_{[t]}^{r} \boldsymbol{q}_{[t]}^{r}
\\ \\&=
\mathbf{S}_{[t-1]}^{C}
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\boldsymbol{q}_{[t]}^{r}
\right)
+
\sum_{i=1}^{r}
\left(
\boldsymbol{u}_{[t]}^i
-
\mathbf{S}_{[t-1]}^{C}
\boldsymbol{w}_{[t]}^{i}
\right)
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1}
\boldsymbol{k}_{[t]}^{i}
\right)^\top
\left(
\text{Diag}(\boldsymbol{\gamma}_{[t]}^r)
\boldsymbol{q}_{[t]}^{r}
\right)
\end{aligned}\]
现在定义:
\[\begin{aligned}
\mathbf{\Gamma}_{[t]} &= [
\boldsymbol{\gamma}_{[t]}^1,
\boldsymbol{\gamma}_{[t]}^2,
...,
\boldsymbol{\gamma}_{[t]}^C
]^\top
\\
\\
\overleftarrow{\square_{[t]}}
&=
\square_{[t]}
\odot
\mathbf{\Gamma}_{[t]}
,\quad
\overrightarrow{\square_{[t]}}
=
\square_{[t]}
\oslash
\mathbf{\Gamma}_{[t]}
\quad\text{for}\quad \square \in \{ \mathbf{Q}, \mathbf{K}, \mathbf{W}\}
\end{aligned}\]
然后我们可以将计算重写为矩阵形式(温馨提示:不要忘记对 O 进行转置):
\[\begin{aligned}
\mathbf{S}_{[t]}^{C}
&=
\mathbf{S}_{[t-1]}^{C}
\text{Diag}(\boldsymbol{\gamma}_{[t]}^C)
+
\left(\mathbf{U}_{[t]}^\top - \mathbf{S}_{[t-1]}^{C} \mathbf{W}_{[t]}^\top \right)\overrightarrow{\mathbf{K}_{[t]}}
\text{Diag}(\boldsymbol{\gamma}_{[t]}^C)
\\
\\
\mathbf{O}_{[t]}
&=
\overleftarrow{\mathbf{Q}_{[t]}} \mathbf{S}_{[t-1]}^{C \top}
+
\left( \overleftarrow{\mathbf{Q}_{[t]}} \overrightarrow{\mathbf{K}_{[t]}}^\top \odot \mathbf{M} \right) \left(\mathbf{U}_{[t]} - \mathbf{W}_{[t]} \mathbf{S}_{[t-1]}^{C \top} \right)
\end{aligned}\]
评论: 这种形式非常自然,该推导再次证明了 DeltaNet 的强大之处。
接下来,我们转向 u_[t] 和 w_[t]。这里,M_{-1} = M - I 表示对角线上为零的严格下三角掩码。
从 u_[t] 的递推式出发,我们得到:
\[\begin{aligned}
\boldsymbol{u}_{[t]}^r
&=
\beta_{[t]}^r
\left(
\boldsymbol{v}_{[t]}^r -
\sum_{i=1}^{r-1}
\boldsymbol{u}_{[t]}^i
\left(\text{Diag}(\boldsymbol{\gamma}_{[t]}^i)^{-1} \boldsymbol{k}_{[t]}^i\right)^\top
\left(\text{Diag}(\boldsymbol{\gamma}_{[t]}^r) \boldsymbol{k}_{[t]}^r\right)
\right)
\\
\\
\Rightarrow
\mathbf{U}_{[t]}
&=
\text{Diag}(\boldsymbol{\beta}_{[t]})
\left(
\mathbf{V}_{[t]} -
\left(
\overleftarrow{\mathbf{K}_{[t]}}
\overrightarrow{\mathbf{K}_{[t]}}^\top
\odot
\mathbf{M}_{-1}
\right)
\mathbf{U}_{[t]}
\right)
\\
\\
\Rightarrow
\mathbf{U}_{[t]}
&=
\left(
\mathbf{I} +
\text{Diag}(\boldsymbol{\beta}_{[t]})
\left(
\overleftarrow{\mathbf{K}_{[t]}}
\overrightarrow{\mathbf{K}_{[t]}}^\top
\odot
\mathbf{M}_{-1}
\right)
\right)^{-1}
\text{Diag}(\boldsymbol{\beta}_{[t]})
\mathbf{V}_{[t]}
\end{aligned}\]
基于相同的理由,我们也有:
\[\begin{aligned}
\mathbf{W}_{[t]}
=
\left(
\mathbf{I} +
\text{Diag}(\boldsymbol{\beta}_{[t]})
\left(
\overleftarrow{\mathbf{K}_{[t]}}
\overrightarrow{\mathbf{K}_{[t]}}^\top
\odot \mathbf{M}_{-1}
\right) \right)^{-1}
\text{Diag}(\boldsymbol{\beta}_{[t]})
\overleftarrow{\mathbf{K}_{[t]}}
\end{aligned}\]
因此,为了计算 U_[t] 和 W_[t],关键的量是:
\[\begin{aligned}
\mathbf{\widetilde{A}}_{[t]}
=
\left(\mathbf{I} + \text{Diag}(\boldsymbol{\beta}_{[t]}) \left( \overleftarrow{\mathbf{K}_{[t]}} \overrightarrow{\mathbf{K}_{[t]}}^\top \odot \mathbf{M}_{-1} \right) \right)^{-1}
\end{aligned}\]
矩阵求逆步骤可以按照与 DeltaNet 笔记中相同的方法进行处理。
五、相关方法
与 DPLR 的对比
\[\begin{aligned}
\mathbf{S}_t
&= \mathbf{S}_{t-1}
(\text{Diag}(\boldsymbol{\alpha}_t) - \boldsymbol{b}_t \boldsymbol{a}_t^\top)
+
\beta_t \boldsymbol{v}_t \boldsymbol{k}_t^\top
\in \mathbb{R}^{d_v \times d_k}
\end{aligned}\]
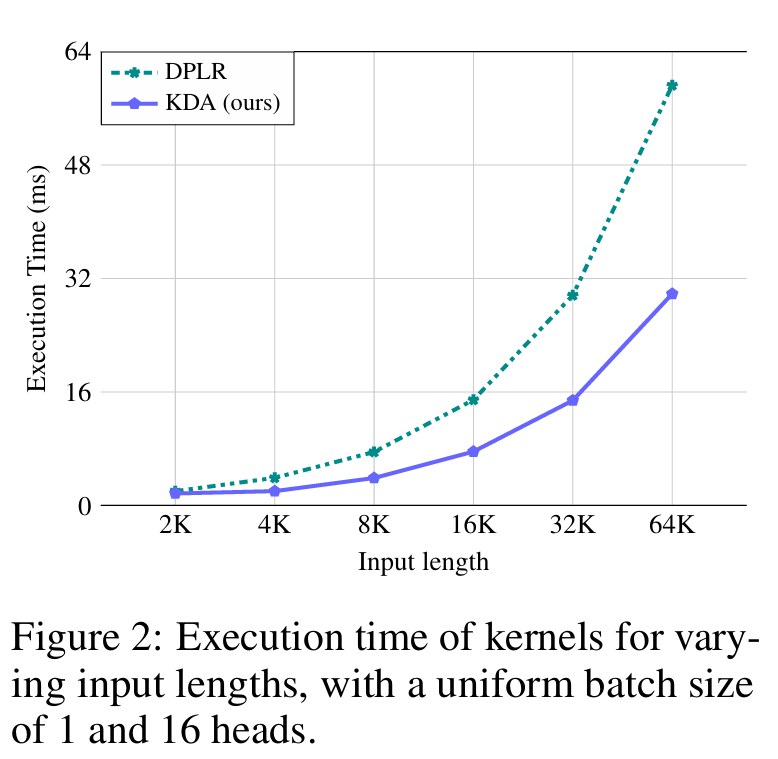
评论(来自原文): 先前的研究(如 GLA)已经指出,当与衰减参数 Diag 交互时,必须高度注意数值精度问题。最好在 全精度下使用 次级分块,这是一种用速度换取稳定性的做法。在 DPLR 中,这可能会导致四个数值极其脆弱的项,即 Q @ K、Q @ B、A @ B、A @ K。KDA 将变量 a 和 b 都绑定到了 k 上,从而将其减少到只有两项,即 Q * K、K @ K。
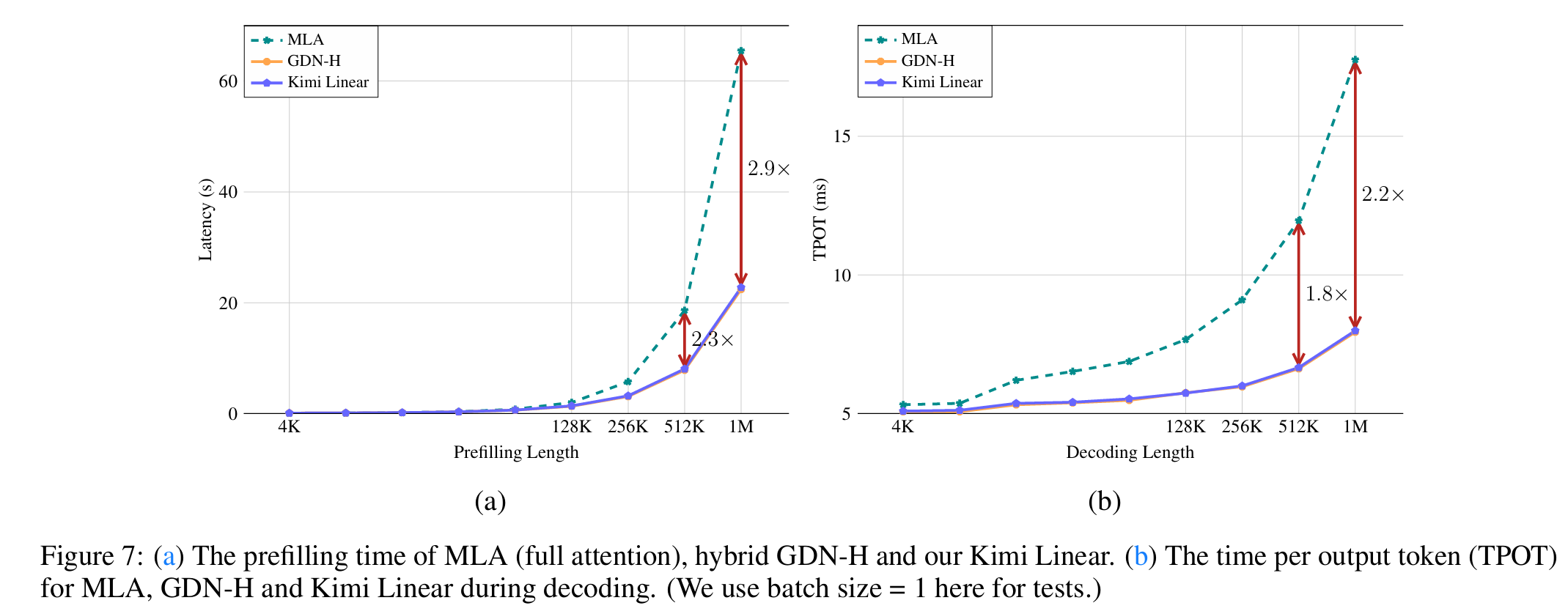
与其他模型的对比

测试时训练的视角

六、实验
模型架构
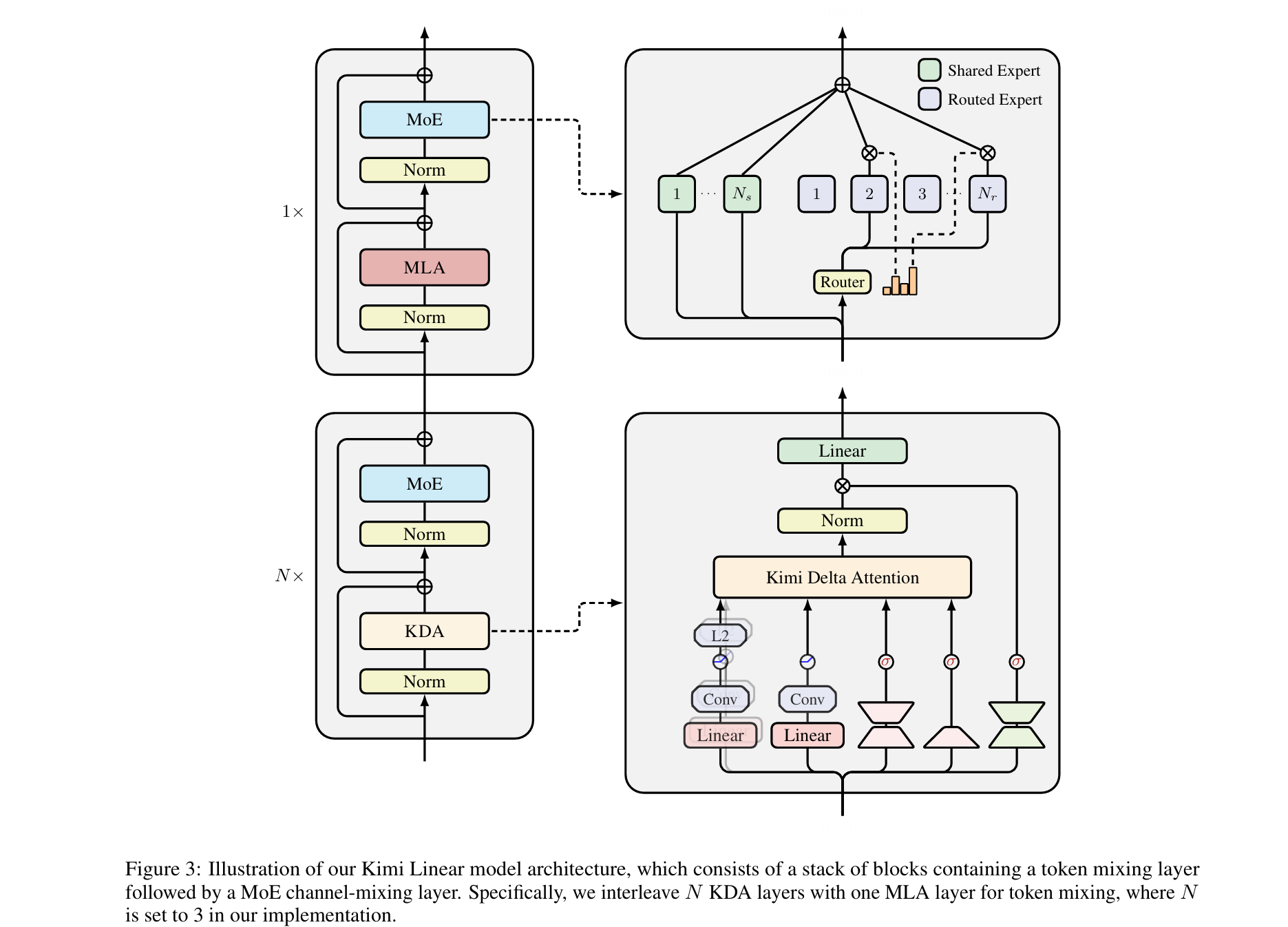
- KDA 层
\[\begin{aligned}
\boldsymbol{q}_{t}^{h}, \boldsymbol{k}_{t}^{h}
&= \operatorname{L2Norm}\left(\operatorname{Swish}\left(\operatorname{ShortConv}\left(\mathbf{W}_{q / k}^{h} \boldsymbol{x}_{t}\right)\right)\right) \in \mathbb{R}^{d_{k}}
\\
\\
\boldsymbol{v}_{t}^{h}
&=\operatorname{Swish}\left(\operatorname{ShortConv}\left(\mathbf{W}_{v}^{h} \boldsymbol{x}_{t}\right)\right) \in \mathbb{R}^{d_{v}}
\\
\\
\alpha_{t}^{h} &=f\left(\mathbf{W}_{\alpha}^{\uparrow} \mathbf{W}_{\alpha}^{\downarrow} \boldsymbol{x}_{t}\right) \in[0,1]^{d_{k}}
\\
\\
\beta_{t}^{h}
&=\operatorname{Sigmoid}\left(\mathbf{W}_{\beta}^{h} \boldsymbol{x}_{t}\right) \in[0,1]
\\
\\
\boldsymbol{o}_{t}
&=\mathbf{W}_{o}\left(\operatorname{Sigmoid}\left(\mathbf{W}_{g}^{\uparrow} \mathbf{W}_{g}^{\downarrow} \boldsymbol{x}_{t}\right) \odot \operatorname{RMSNorm}\left(\operatorname{KDA}\left(\boldsymbol{q}_{t}, \boldsymbol{k}_{t}, \boldsymbol{v}_{t}, \boldsymbol{\alpha}_{t}, \beta_{t}\right)\right)\right)
\end{aligned}\]
门控 \(\alpha_t^h\) 的计算方式为 \alpha_t^h = -exp(A_log) * softplus(W^up W^down x + dt_bias),这类似于 mamba。其中A_log 的形状为 [H],而 dt_bias 的形状为 [H * K]。
-
层间混合
Kimi Linear 使用了 3:1 的 KDA 与 MLA 比例。选择层间混合而不是层内混合(例如每个头分别采用不同的attention)的主要原因是 infra 更为简单。
-
为 MLA 使用 NoPE
MLA 使用 NoPE,因为 KDA 能够通过其循环衰减机制天生地捕获位置信息。这种设计对于长上下文的外推也非常有益。
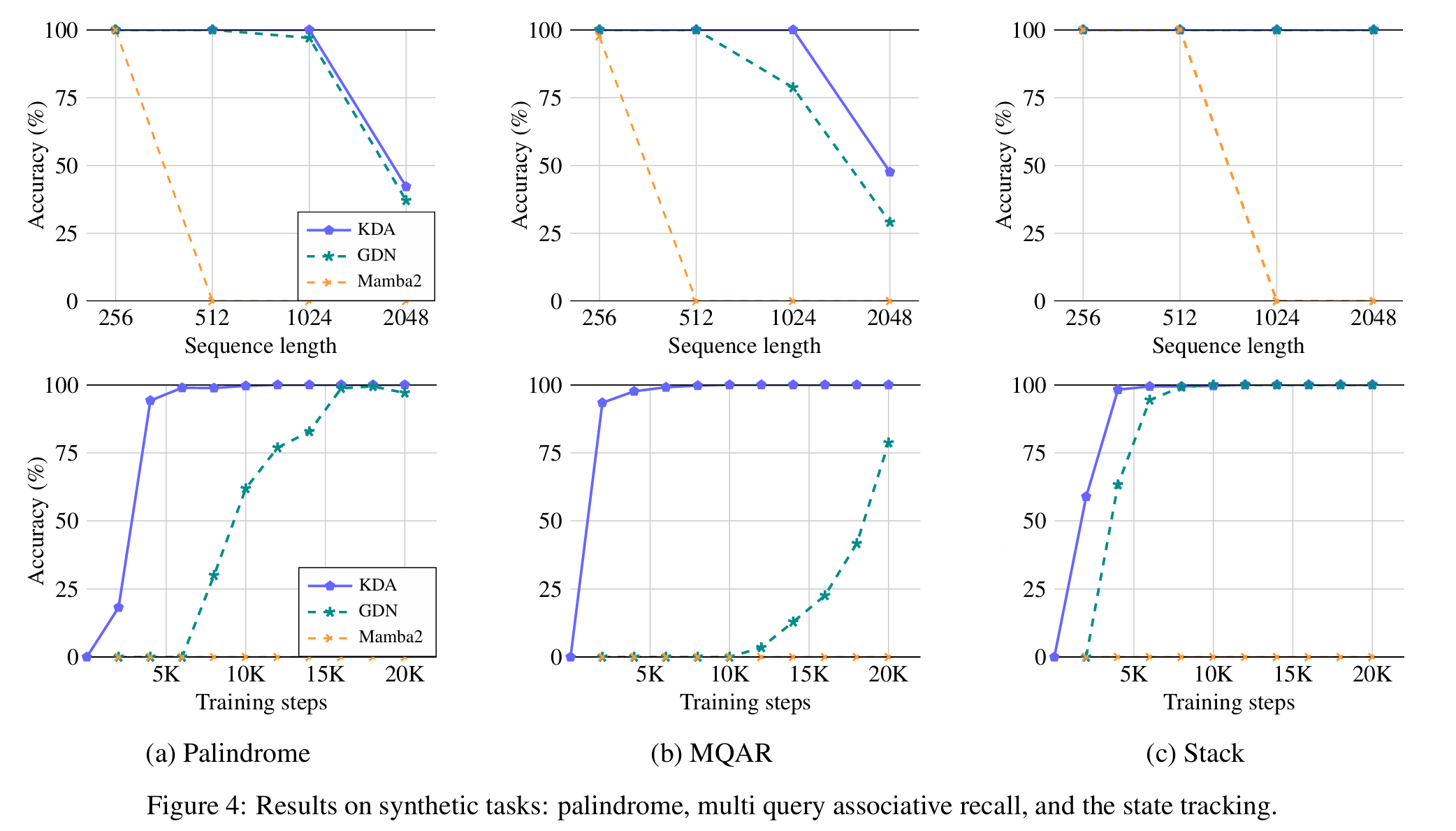
合成数据测试
Palindrome 生成反转序列

Multi Query Associative Recall (MQAR) 输出下一个
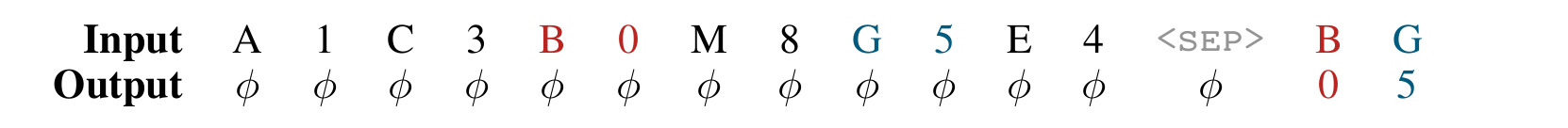
Stack 具有后进先出 (LIFO) 的栈操作
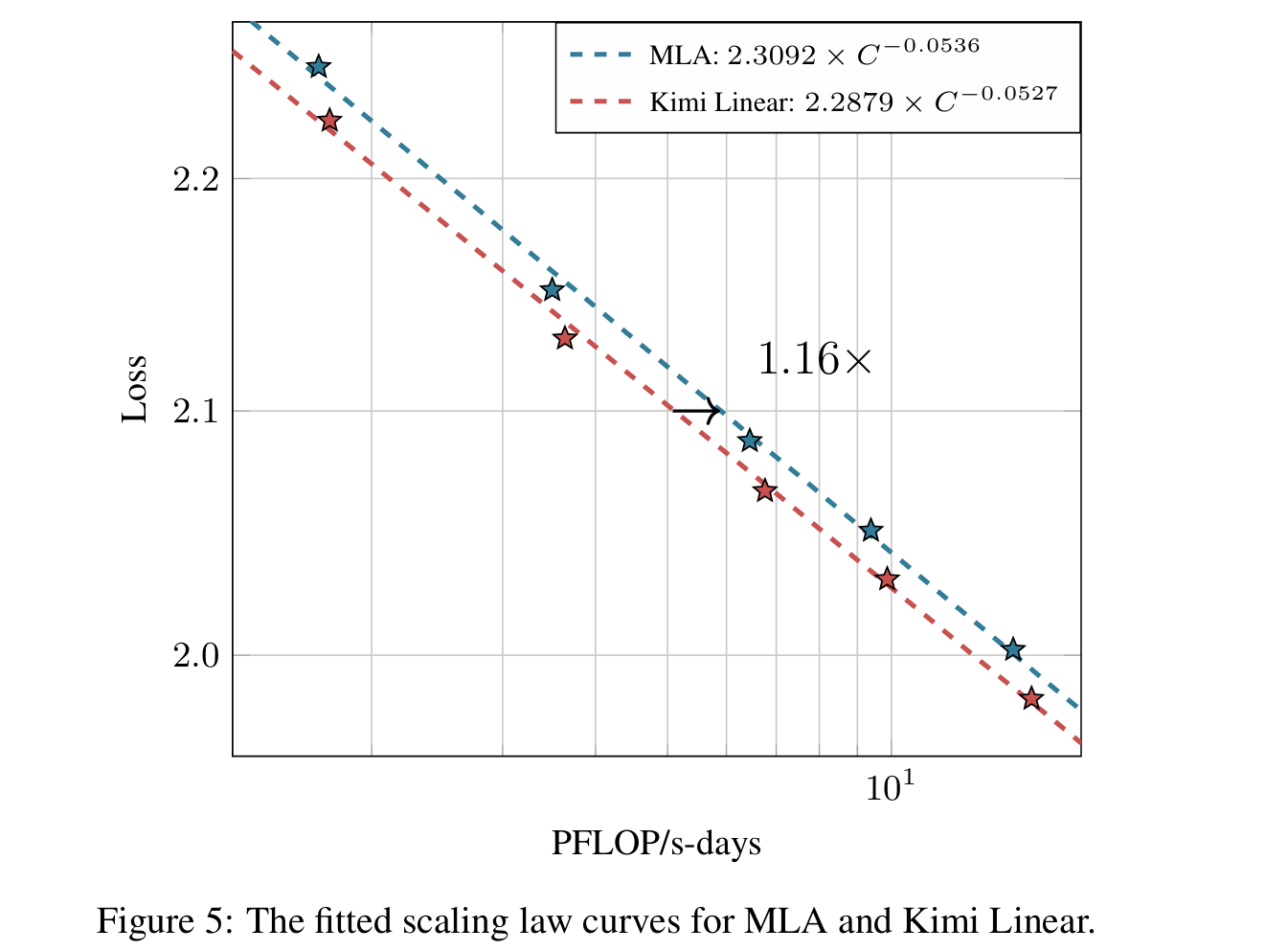
缩放定律
- 基座:MoE Moonlight 架构
- 激活专家 / 总专家数:8 / 64
- 优化器:Muon Optimizer
- 使用了 Chinchilla 缩放定律
语言建模
预训练
- 基座 MoE Moonlight 架构
- 激活专家 / 总专家数:8 / 256,包含一个共享专家
- 48B-A8B 规模
- 4096 上下文窗口
- Muon Clip 优化器
- WSD 学习率调度
- 来自 K2 预训练语料库的 1.4T tokens
- 学习率设置为 1.1 × 10−3
- 全局 batch size 固定为 32M tokens
- 与 Kimi K2 中确立的退火调度和长上下文激活阶段相同
后训练: SFT
- Kimi K2 SFT 数据 + 额外的推理任务
- 多阶段 SFT 方法:最初用于通用指令遵循,随后是推理密集型数据
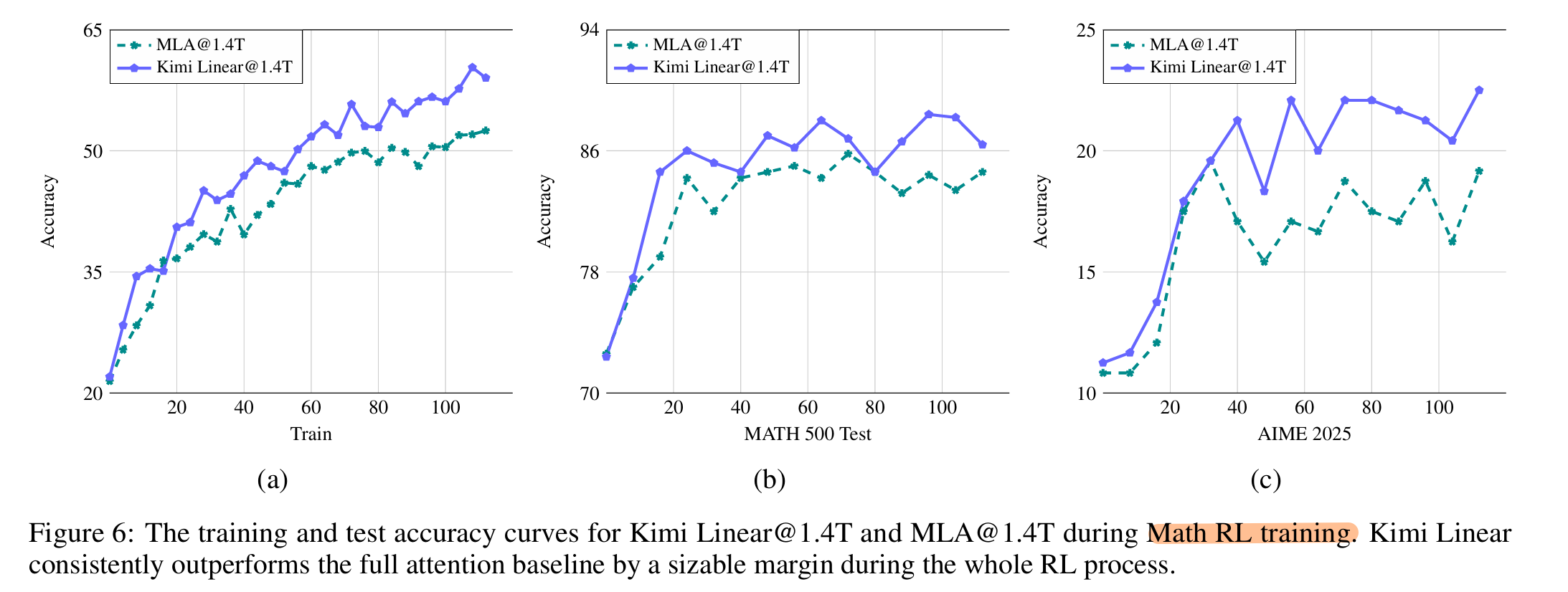
后训练: RL
- 来自 Kimi K2 数据的数学、代码和 STEM 任务,筛选出对于起始权重为中等难度的数据。
- 额外的 PTX loss。PTX dataset涵盖了推理和通用任务。
[注意] 后训练: RL
训练和推理引擎之间的精度不匹配可能会导致RL 学习不稳定 -> 采用截断的重要性采样,动态调整 KL 惩罚项以及 mini batch 大小。
评估
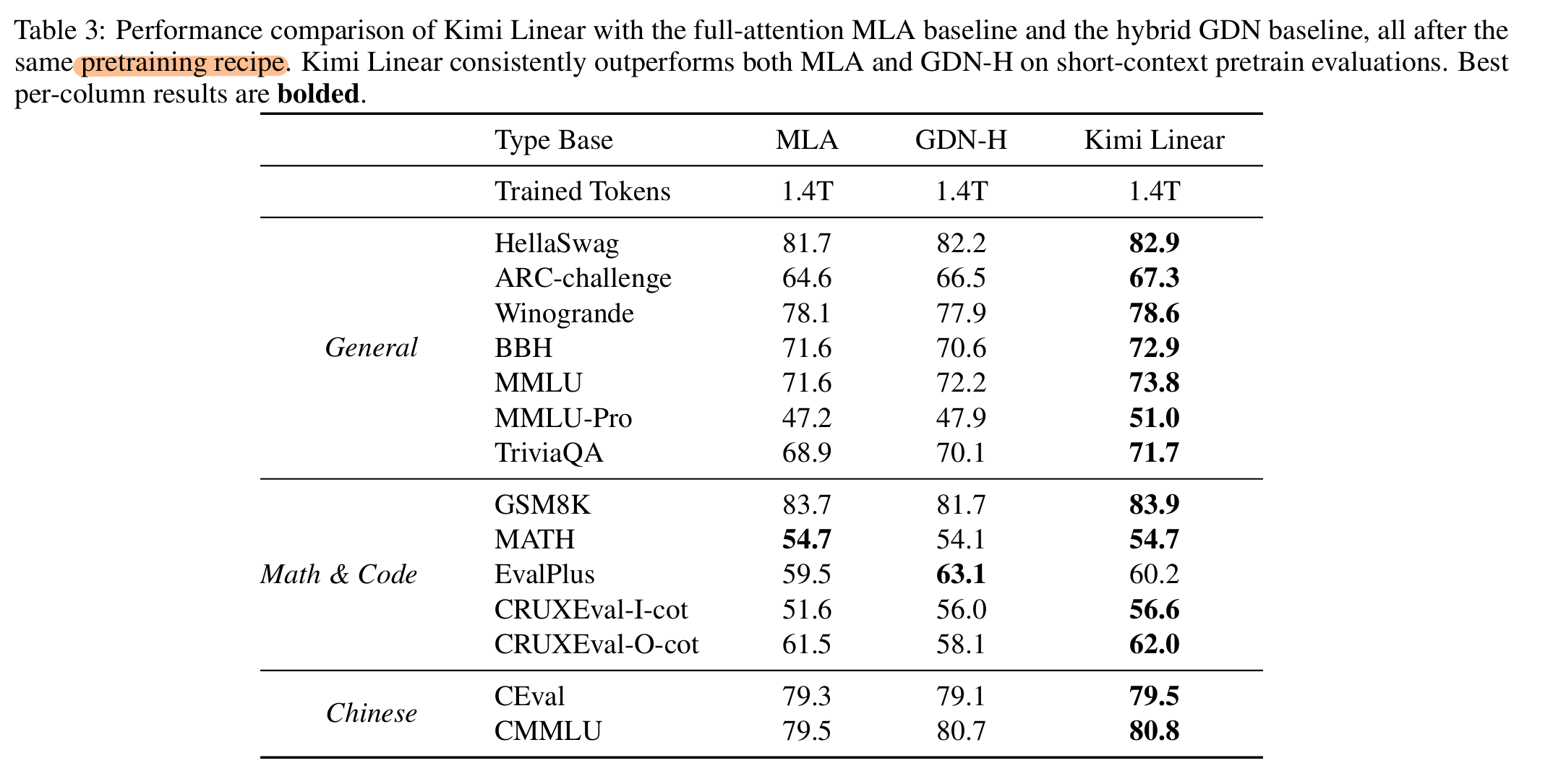
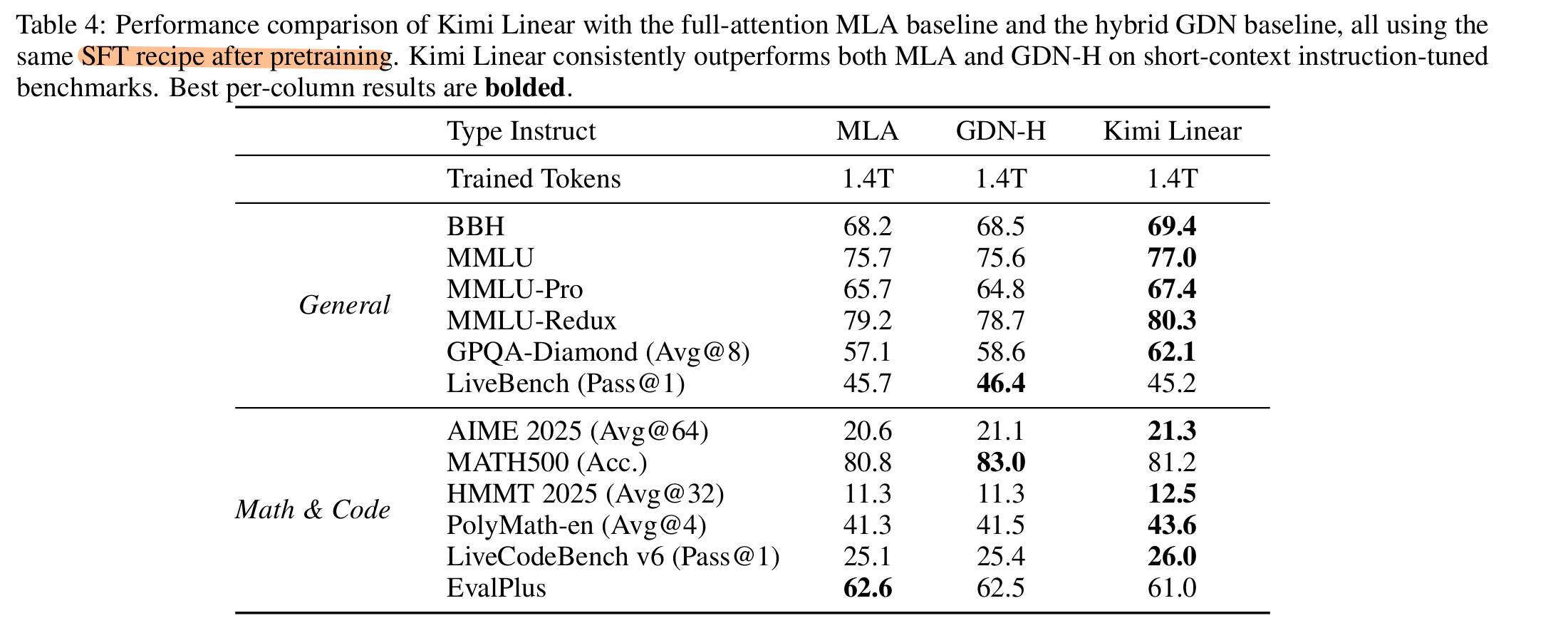
- 语言理解与推理: Hellaswag, ARC-Challenge, Winogrande, MMLU, TriviaQA, MMLU-Redux, MMLU-Pro, GPQA-Diamond, BBH, Livebench.
- 代码生成: LiveCodeBench v6, EvalPlus
- 数学和推理: AIME 2025, MATH 500, HMMT 2025, PolyMath-en.
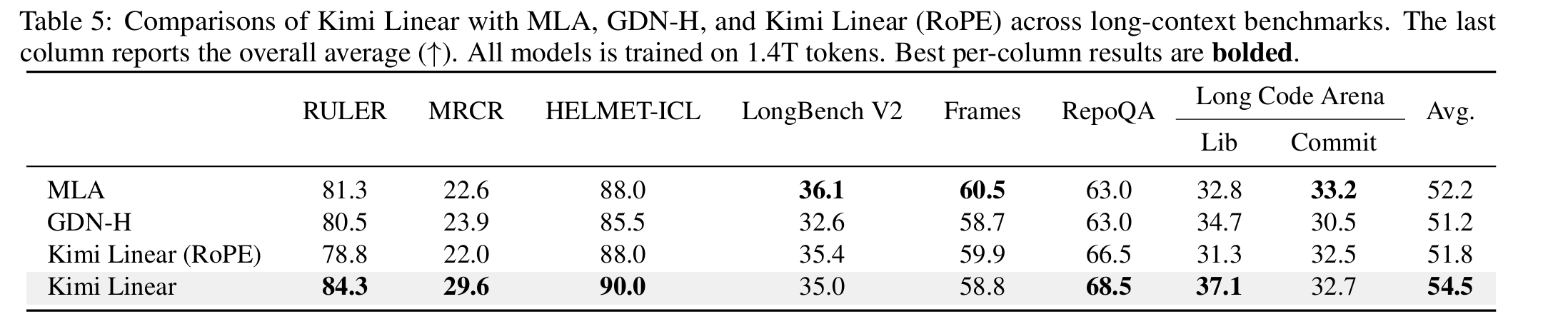
- 长上下文: MRCR 5 , RULER, Frames, HELMET-ICL, RepoQA, Long Code Arena, LongBench v2.
- 中文语言理解与推理: C-Eval, and CMMLU.
- Temprature=1.0, LM-Harness-Evaluation
- Base模型对 MMLU, MMLU-Redux, GPQA-Diamond, and C-Eval 采用基于PPL的评估, 其他情况使用基于生成的评估.