A Naive Design of Interleaved Multimodal Models for Document Understanding and Generation¶
Comments: This technical memoir is a retrospective on the design of a native, interleaved image-text large multimodal model developed in 2024 (during my internship in MSRA). This document formalizes part of the engineering decisions, empirical observations, and mathematical optimizations implemented during the project. The architectures described below may introduce novel ideas or simply leverage methodologies existing in or before 2024. As a personal retrospective, formal citations are omitted, but we express our deepest appreciation for the incredible pioneering work done by the community.
Introduction¶
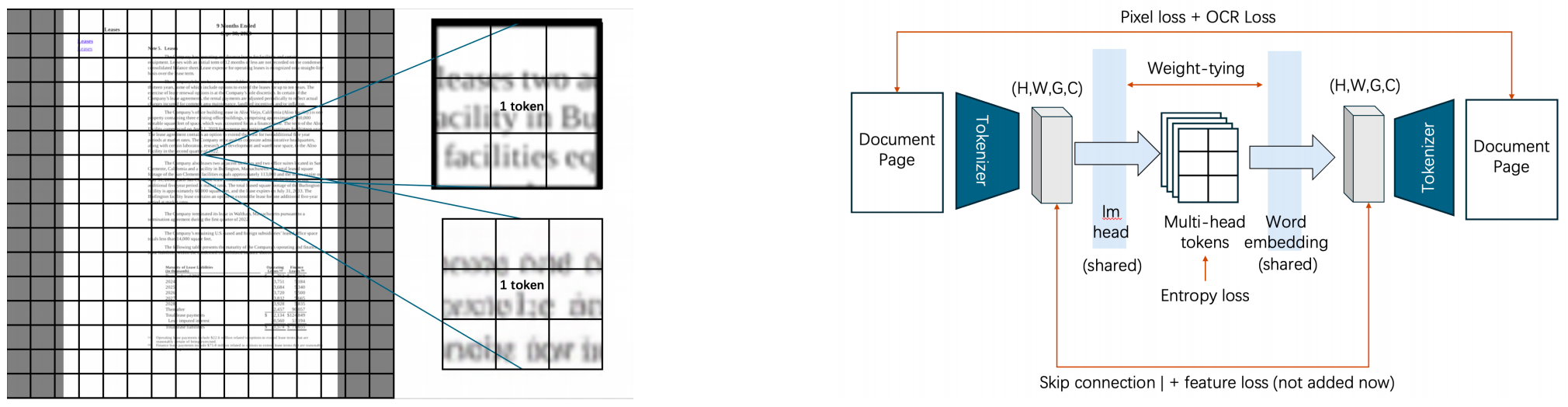
The core objective of this project was to implement a natively unified multimodal architecture that capable of both writing words into images and reading content from them. Rather than treating visual data as auxiliary continuous embeddings injected into a language model, this approach unifies the input streams by merging discrete text vocabularies with quantized vision codebooks into a single, combined vocabulary.
The Vision Tokenizer¶
The Overall Framework¶
Data¶
Data Format¶
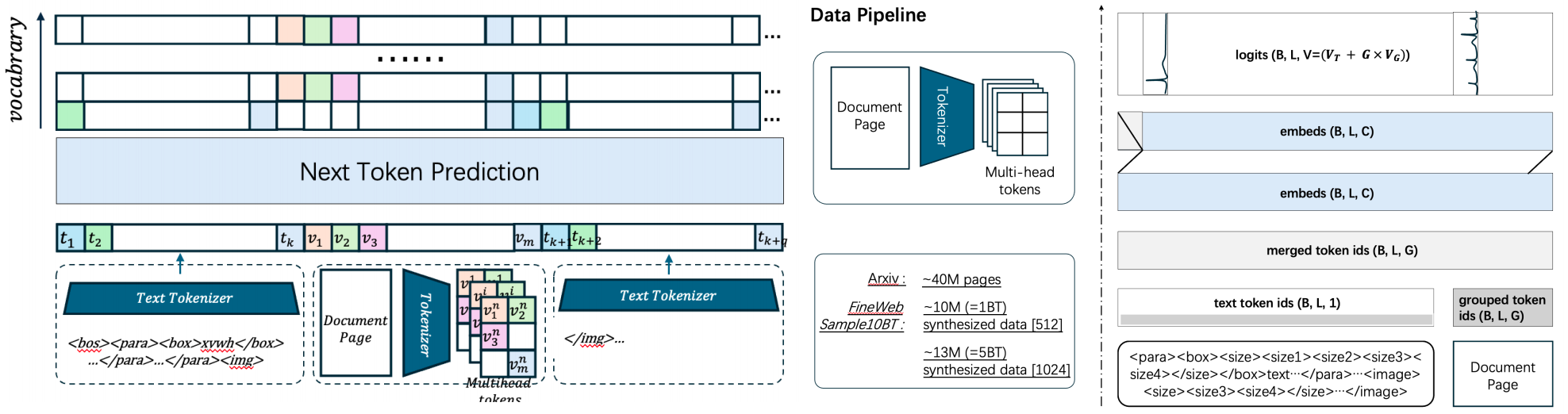
To train an interleaved document-level model capable of parsing and understanding layout structures, spatial topology must be passed directly to the language model. We experimented with two distinct data formatting paradigms to teach the model how to auto-regressively generate bounding boxes and layout configurations.
Format A: Explicit Spatial Anchoring (With Bounding Boxes) To explicitly guide document layout parsing, textual segments are bounded by structural tags paired with absolute, normalized coordinates:
<para><box><size{x1}><size{y1}><size{x2}><size{y2}></box>It's a good day...</para>... <image><size><size{w}><size{h}></size><image_pad1>...</image><para>...
Format B: Implicit Spatial Inference (Without Bounding Boxes) This format strips structural coordinates, tasking the model's internal hidden states with learning spatial layout dependencies implicitly:
<para>It's a good day...</para>... <image><size><size{w}><size{h}></size><image_pad1>...</image><para>...
However, attempting to force a compact 2B backbone model to learn both data formats concurrently proved overly ambitious, introducing excessive variance that hindered convergence. Consequently, we standardized completely on Format A to provide strict layout constraints.
Data Source¶
-
The arXiv Corpus: An OCR-centric dataset containing dense page layouts. Text content is strictly aligned with ground-truth bounding boxes, mapping semantic units directly to their spatial positions on the corresponding page images.
-
The Synthetic Dataset: To enhance layout robustness, raw text extracted from FineWeb was compiled into clean, white-paper PDF layouts via
PyMuPDF (fitz). Synthesized documents utilized randomized font families, sizes, weights, and color configurations to expand data diversity.
Multi-Head Vision Tokenizer¶
When developing the discrete visual tokenizer, we established three core empirical observations:
-
Reconstruction Degradation: Utilizing overly large visual patch dimensions significantly degrades spatial reconstruction quality and removes fine-grained details.
-
Semantic Fragmenting: Overly localized, hyper-granular patches fail to capture unified semantic meaning. Such patches often contain nothing more than meaningless local curves, making it difficult for the model to extract high-level semantic concepts.
-
Embedding Dimensional Mismatch: The natural hidden dimensionality (width) of native vision codebooks is narrower than the expansive text embedding space of LLMs.
To resolve these trade-offs, we designed a Multi-Head Vision Tokenizer.
Instead of forcing a visual patch into a single integer index within an enormous discrete vocabulary, a wide spatial patch rich in global semantics is projected through \(G\) distinct linear heads. Each individual head points to its own discrete allocation pool within an overall image codebook matrix. This produces a composite integer vector \(\boldsymbol{t} \in \mathbb{R}^{G}\) per visual patch, binding multiple integers to a single patch to ensure high-fidelity reconstruction.
To address the third observation (embedding width mismatch), the projection heads are merged and projected into the unified high-dimensional hidden space of the backbone model, which in our setup was Gemma-2 2B.
To tailor the performance specifically for document generation, we incorporated a diverse combination of auxiliary loss functions during tokenizer training.
Combined Vocabulary Representation¶
The vocabulary structure simply appends the \(G \times \text{codebook}\) entries directly behind the pre-existing text vocabulary. Sequence targets are uniformly represented by a sequence of vectors \(\boldsymbol{t} \in \mathbb{R}^{G}\):
* For Image Tokens: The \(G \times \text{integers}\) in \(\boldsymbol{t}\) map to their respective indices in the \(G\) split image codebooks. The corresponding embedding of those \(G\) ids would get merged and projected into a single embedding.
* For Text Tokens: For computing convenience, the \(G \times \text{integers}\) in \(\boldsymbol{t}\) are duplicated to carry the exact same number, representing the standard token_id within the language vocabulary. In the text embedding layer, only a single token ID is actively used to bind and retrieve the language embedding.
This unified vocabulary layout prevents modality-specific isolation during training. Deliberately isolating image optimization from text optimization distorts the next-token probability distribution, breaking the multimodal synergy we want the transformer to learn natively.
To clarify, we hypothesize that a primary reason for the sub-optimal vision performance in some models developed in and before 2024 is the inability to preserve the subtle distinctions between visual tokens and textual tokens. In our design, they are purposely treated as distinct entities.
To use an analogy within language itself: words like "sparrow," "eagle," and "penguin" all fall under the broad category of "bird," yet they occupy distinct, parallel positions in the embedding space as unique entities.
Following this logic, concepts extracted from images should not be forcibly collapsed into existing text coordinates. Instead, the visual "bird" and the textual "bird" should behave like two different species within the same conceptual family, coexisting as parallel synonyms separated by subtle semantic boundaries, with their exact geometric relationships left for the model and data to dynamically determine.
Mixed-Target Cross-Entropy Loss¶
Given a vocabulary set \(\mathcal{V}\), true distribution probability \(p_t\), and predicted logit configurations \(l_t\), standard cross-entropy loss with one-hot targets simplifies to tracking the active positive token:
The gradient propagation is formulated as:
When dealing with non-one-hot targets, standard implementations introduce full dense multiplications between huge vectors \(\boldsymbol{p} \in \mathbb{R}^{|\mathcal{V}|}\) and \(\boldsymbol{l} \in \mathbb{R}^{|\mathcal{V}|}\), causing severe memory overhead.
To optimize this, we restrict target tracking strictly to a sparse subset index space \(\mathcal{G} \subseteq \mathcal{V}\) via torch.gather:
To scale execution, the global vocabulary logits are partitioned across \(N\) physical accelerator cards. On a given card \(k\) managing local partition \(\mathcal{V}^k\), distributed reductions are calculated as follows:
During the backward pass, we precompute and cache the global softmax states \(S(l_i) = \exp(l_i) / \sum_{k}\mathcal{L}_{\text{CE, neg}}^{k}\) inside the forward pass to avoid redundant activation materialization. We then apply torch.gather to extract only the active items within \(S(l_i)\), subtract the target probabilities \(p_i\), and use an inplace scatter operation to populate the gradients, bypassing full tensor allocation.
Attention Masking Paradigms¶
We explored two distinct autoregressive sequence-masking strategies to manage text-image interleaving.
Strategy A: Pure Next-Token Prediction¶
The first choice applies standard causal Next-Token Prediction uniformly across all modalities. It processes text and discrete image tokens within a single unified sequence, treating image indices exactly like standard text tokens. This forces the model to learn modality shifts entirely on its own. Due to its robustness and engineering simplicity, this strategy was chosen in this project.
Strategy B: Hybrid Next-Block Prediction¶
The alternative paradigm enforces standard sequential NTP for text segments while transitioning to parallelized block generation for image regions.
When the model encounters the layout tag <image><size><size{w}><size{h}></size>, it triggers a shift into image mode for the subsequent \(w \times h\) tokens. The causal attention matrix is modified to allow parallel block extraction.
The attention mask layout follows this causal structure:
| AttnMask | |||||||
|---|---|---|---|---|---|---|---|
<size{h}> |
1 | ||||||
</size> |
1 | 1 | |||||
<p1> |
1 | 1 | 1 | 1 | 1 | ||
<p2> |
1 | 1 | 1 | 1 | 1 | ||
<p3> |
1 | 1 | 1 | 1 | 1 | ||
</image> |
1 | 1 | 1 | 1 | 1 | 1 | |
<para> |
1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q / K | <size{h}> |
</size> |
<p1> |
<p2> |
<p3> |
</image> |
<para> |
Under this block-masking setup, prediction targets shift as follows:
| Prediction | |||||||
|---|---|---|---|---|---|---|---|
| Source | <size{h}> |
</size> |
MASK |
MASK |
MASK |
</image> |
<para> |
| Target | </size> |
NULL |
<p1> |
<p2> |
<p3> |
<para> |
NEXT |
While this hybrid approach deviates from our core belief that all tokens should remain perfectly equal and uniform within the unified embedding space, it provides a highly compelling framework for parallelized visual synthesis.
Future Vision¶
Looking back from the vantage point of 2026, the architectural limitations of our 2024 design are somewhat naive. Moving toward a latent multimodal language model would undoubtedly yield superior representation and generation quality.
Yet, beneath these limitations lies a vast, unexplored design space that points toward a fundamentally different path. We believe biomimicry remains a highly compelling alternative path for multimodal architecture. Human vision does not process the world by throwing massive, high-resolution pixel matrices into a static attention window; instead, it relies on a continuous, low-resolution video stream combined with active, intent-driven scanning.
This inspires the concept of the Glimpse Model, an active-perception architecture defined by three core components:
-
A Fixed-Resolution Encoder: An encoder (or tokenizer) locked into a static, unchanging resolution, allowing the underlying hardware and attention kernels to be aggressively over-optimized. For example, visual inputs are encoded into an autoregressive information flow with a strictly fixed sequence length, ensuring a more seamless alignment with the text-based concept backbone.
-
A Crop-and-Resize Engine: An execution tool controlled directly by the LLM backbone's action tokens. It acts as a digital "fovea," slicing specific high-resolution regions of interest from the raw input and normalizing them to feed back into the fixed encoder.
-
A Resized Global View: A heavily downsampled, blurred abstraction of the entire visual field. This serves as the model’s "peripheral vision," providing persistent spatial and topological context without bloating the sequence memory. Ultimately, the model itself decides where to look, when to look, and what to focus on.
We hope that someday, an elegant Glimpse Model will emerge from the community and fundamentally redefine how AI conquers the vision task.